The paper outlines a technique for production-grade chat applications (conversational agents):
- It models the ideal conversation between parties as a Directed Acyclic Graph (DAG)
- Each node in this graph is a
stateof a conversation - Each node has its own prompts and tools and manipulates the state with:
- Few-shot examples
- Constrained decoding for output generation and graph traversal
- The paper also demonstrates a method for fine-tuning models for this setup
Motivation of the Author
- Building reliable conversational agents
- The probabilistic nature of the model means it can randomly fail to comply with business requirements
Node Structure and Motivation
- The paper claims that LLMs often struggle with complex conditionals (which is true)
- By providing structure to each
node, stability is increased - Structure of Each Node:
- A system prompt with few-shot examples
- A custom computational routine that manipulates the history/context (to prevent LLM hallucinations)
- Tool calls obtained using constrained decoding (structured outputs)
Example Graph
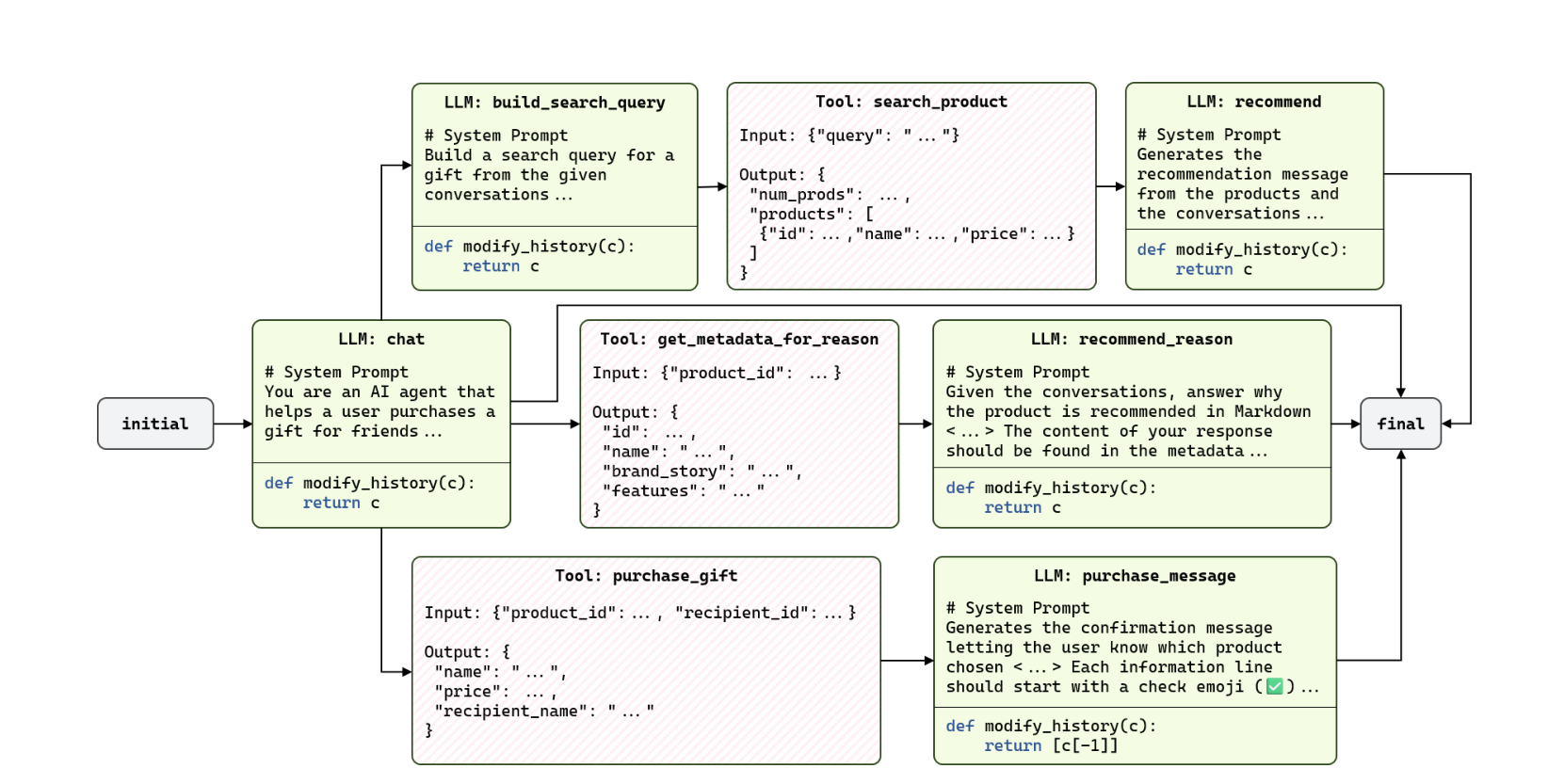
- At each conversation turn, we start at the initial node, and the first LLM call either:
- Directs toward a tool/another LLM call (task-specific request) or
- Handles non-task-specific queries just like a normal LLM
- At last we reach the final state which gives the final output to the user
Analysis
While the DAG approach provides additional structure, it bears strong resemblance to standard tool calling patterns. The key difference seems to be the output generation step which has its own node-specific system prompts, which could provide better output control compared to having a single system prompt. The programmatic graph structure could also be helpful in increasing the accuracy of long chains of tool calls required for a single input.
Fine-Tuning: Data Generation
Problem: Making appropriate (input, output) pairs
- Tasks such as “Recommend me a wine that goes well with X” are complex and require multi-step reasoning
- Difficult for annotators to write the desired response
- So GPT-4o was used (prompted with the DAG) to get baseline data, which was then corrected by annotators
Fine-Tuning: With Response Mapping
Problem:
- In a DAG, responses are generated with multiple system prompts, since there are multiple nodes each with their own prompts
- This can hinder the model’s ability to follow system prompts properly because there can be conflicting system prompts
Solution: They apply loss masking to exclude responses generated by other nodes (with different system prompts)
Evaluation: Dimensions
- Accuracy: Did it use the correct tools? Arguments checked using LLM as a judge (as LLM responses can be quite flexible)
- Format Adherence: Is the output structure exactly as desired? Checked with a coded validator
- Response Validity: Comparison with annotators’ responses, again using LLM as a judge
Evaluation: Architectures
They compared these architectures:
- Baseline: A single system prompt to represent the entire DAG
- Workflow Graph: The DAG architecture
- Workflow Graph + Fine-tuning: The DAG architecture with their proposed fine-tuning
Their results show that their proposed methodology increases performance across all evaluation dimensions. They claim that their internal model augmented with these techniques performs better than GPT-4o. One model, GPT-4o-2024-11-20, already has very high baseline performance which further increases with their methodology.
Personal Addition
I worked on a similar problem at my job and used the baseline(gpt-4o-2024-11-20) approach for this. The graphs that we needed to follow were much more complex, and as a result, the accuracy was notoriously bad. While tackling this, we independently stumbled upon something like the think tool from Anthropic, which greatly increased the accuracy. Combining this paper’s DAG structure with explicit reasoning steps could potentially give even better results.